Visualizing breast cancer transcriptomes
M Hallett
21/07/2020
Clinical perspective of breast cancer (BC)
- Most commonly diagnosed cancer among Canadian women
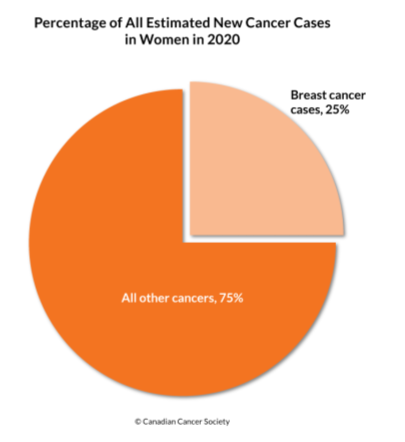
- 25% of all cancers in women (1 in 9 women will have BC in their life time)
- 2nd leading cause of death from cancer.
- In Canada 2020, ~27,400 new breast cancer cases
- and 5,100 breast cancer deaths
- Men are also susceptible (not common)
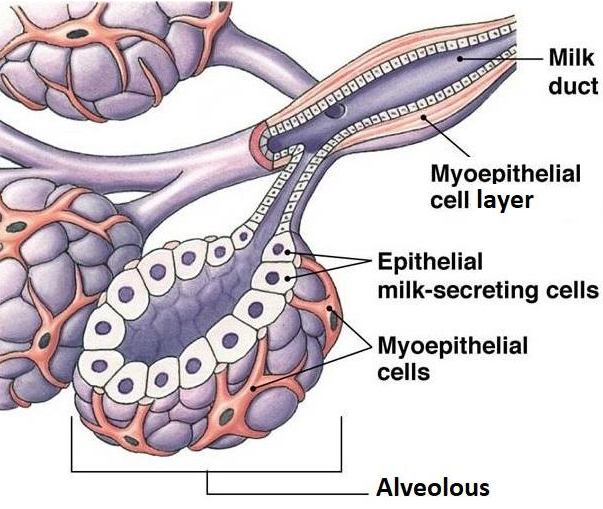
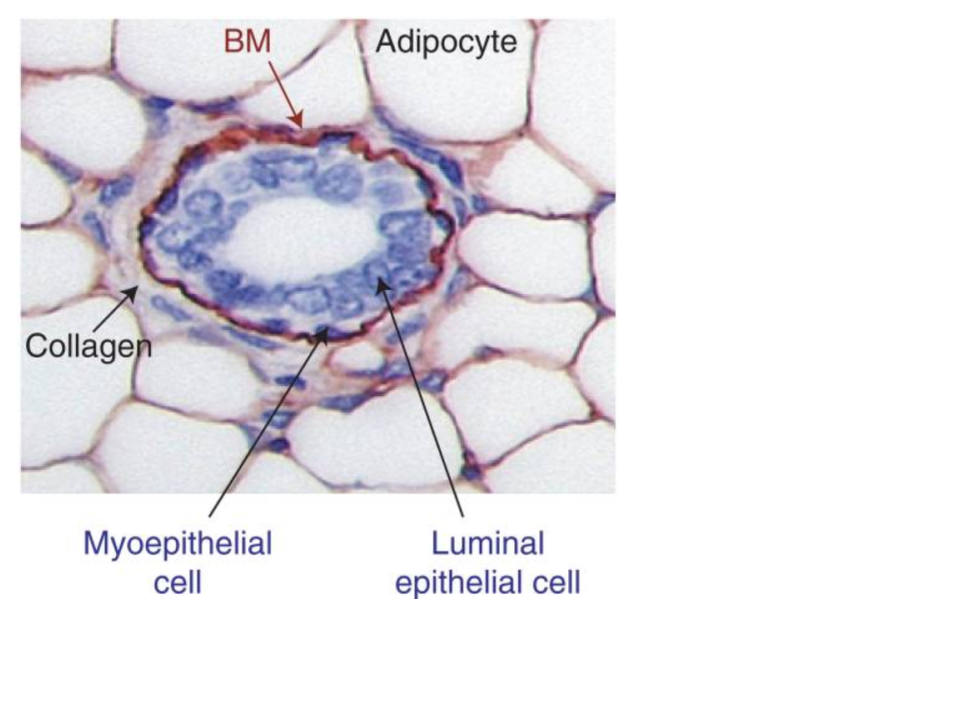
Ductal breast carcinoma
Ductal in situ and invasive breast carcinoma begins in the cells of the duct.
Tumor progression
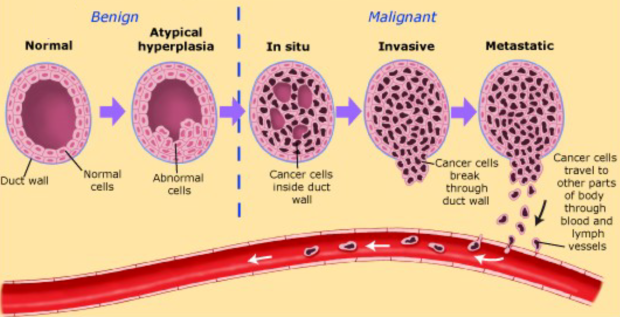
Ductal Breast Cancer
- Clinical oncologists consider many types of information when deciding the therapeutic avenue for a breast cancer patient.
- Tumour, Node, Metastasis (TNM) staging systems describe the extent of the breast cancer in the patient.
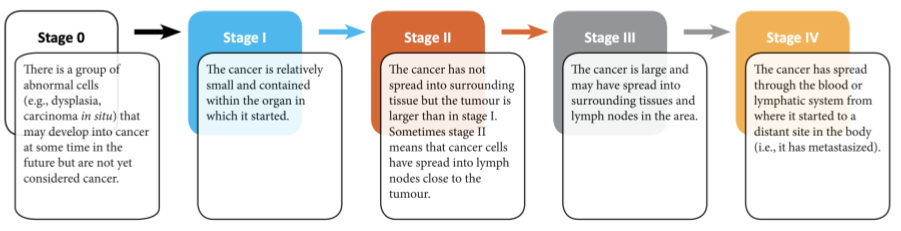
- There are many additional ways that clinical and molecular oncologists evaluate a breast tumor.
- Examples: Tumor grade, proliferative index, estrogen receptor status, progesterone receptor status, HER2 amplification.
- This information is combined with patient attributes including age, lifestyle, BMI, genotype, history etc.
Immunohistochemistry (IHC) for key breast cancer proteins
Estrogen (ER) and Progesterone (PR) Receptors, and Human Epidermal Growth Factor (HER2)
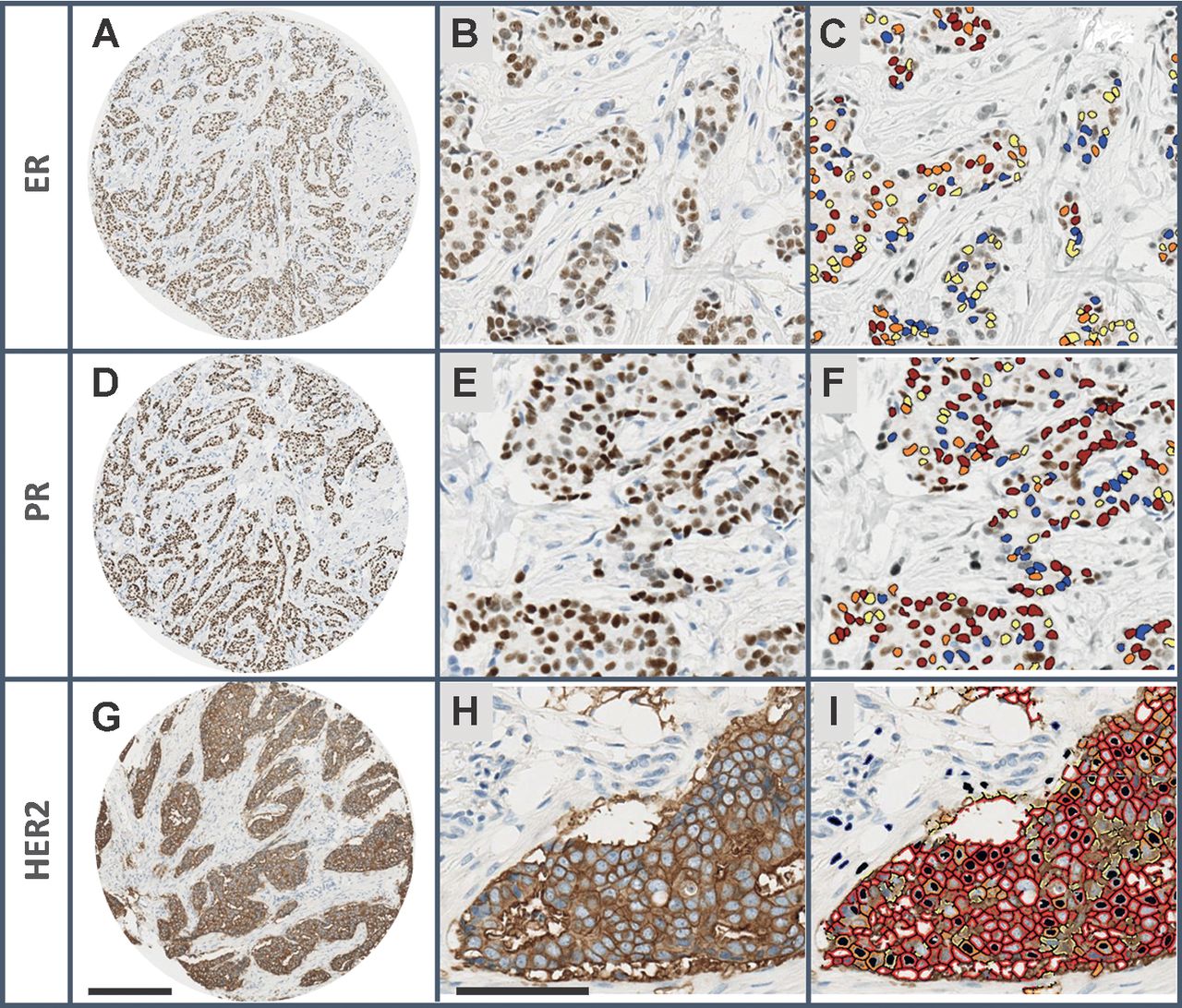
The expression of these three proteins has been used for \(30\) years to classify breast tumors into subtypes.
Tumors of the three subtypes have very different clinical and molecular characteristics.
Each subtype has different treatments. For example, Tamoxifen for ER+ tumors and Herceptin for HER2+ tumors.
-In clincial settings, HER2 status is usually measured by Flourescence In Situ Hybridization (FISH).
Subtypes of breast cancer
High-throughput profiling of the transcripts (gene expression profling or “transcriptomics”) has provided a more robust detailed perspective on BC hetergeniety.
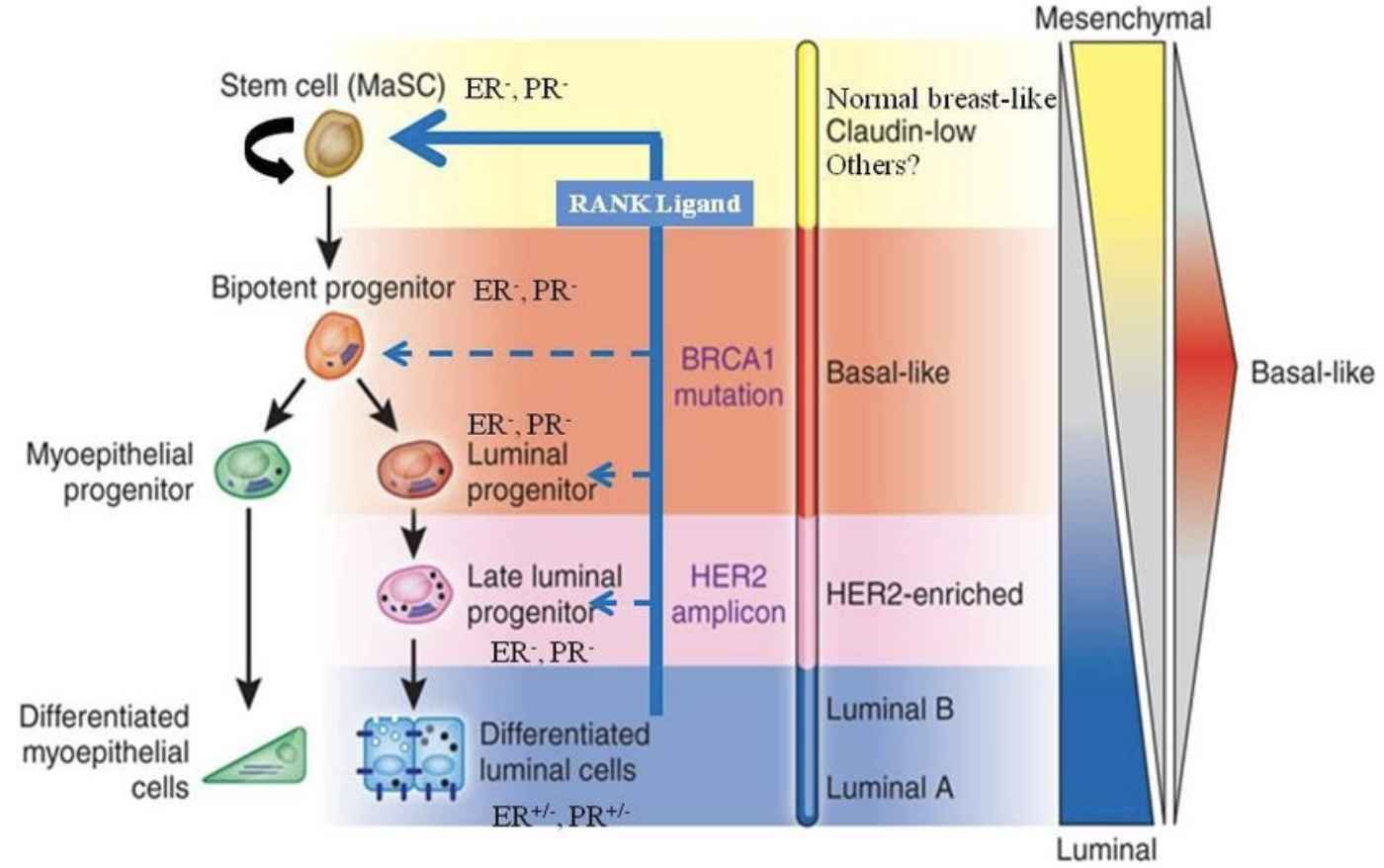
- It is not just ER, PR and HER2. Many genes (and gene products) combine to determine the molecular subtype of a tumor.
Sequencing by Synthesis (Illumina technologies)
Sequencing by Synthesis I would recommend starting with this one. It is quite high level. [From Henrik’s World]
Sequencing by Synthesis II This video is more detailed, providing my background information on the underlying chemistry. [Eric Chow, UCSF]
The Cancer Genome Atlas (TCGA)
- TCGA is a USA project across several institutes (incl The National Cancer Institute) that has profiled \(> 20,000\) tumors (with matched normal) across \(33\) different cancer types.
- Each tumor/sample has a rich array of clinical, pathological and lifestyle information.
- Each tumor/sample is profiled by different technologies including genomic (DNA sequencing), epigenomic (methylation profiles), transcriptomic (gene expression), and proteomic (protein expression) data for each tumor sample.
- The data is publicly available and can be used by researchers to explore cancer.
- I would recommend you read a little bit about the TCGA project here
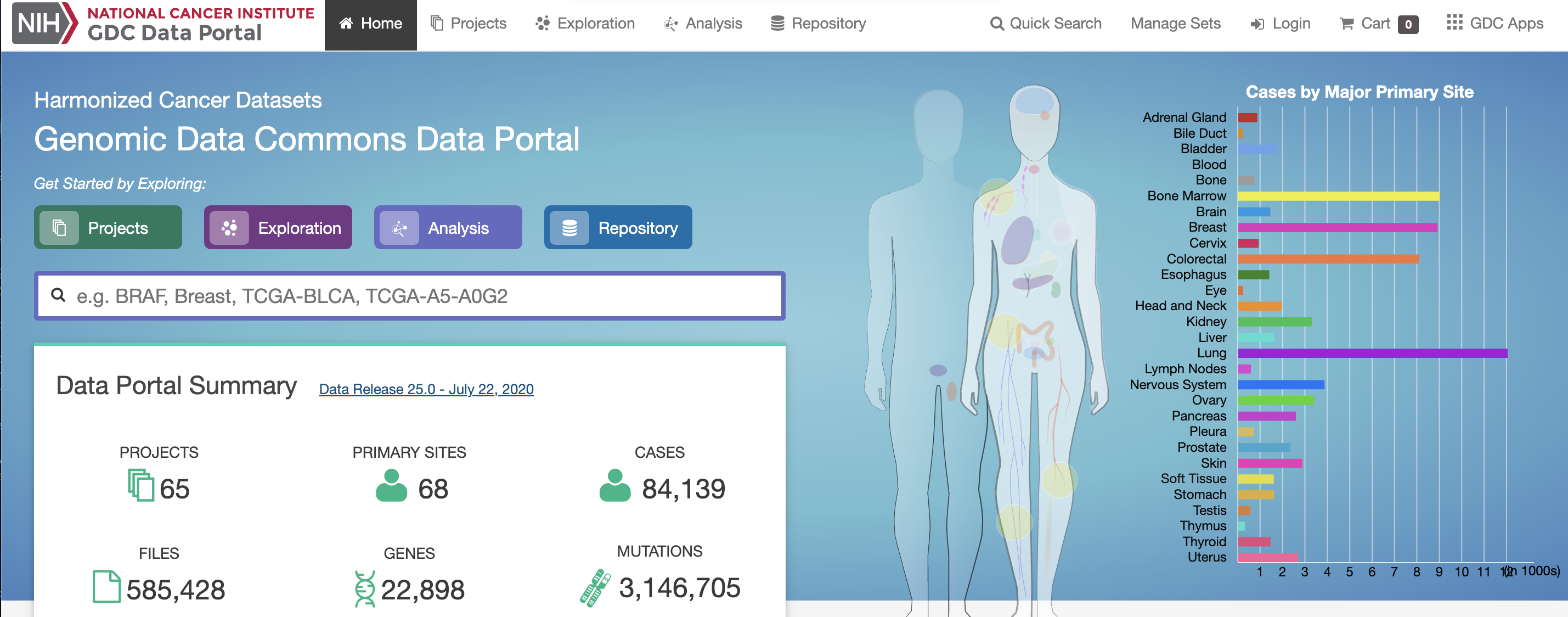
A minaturized TCGA BC dataset
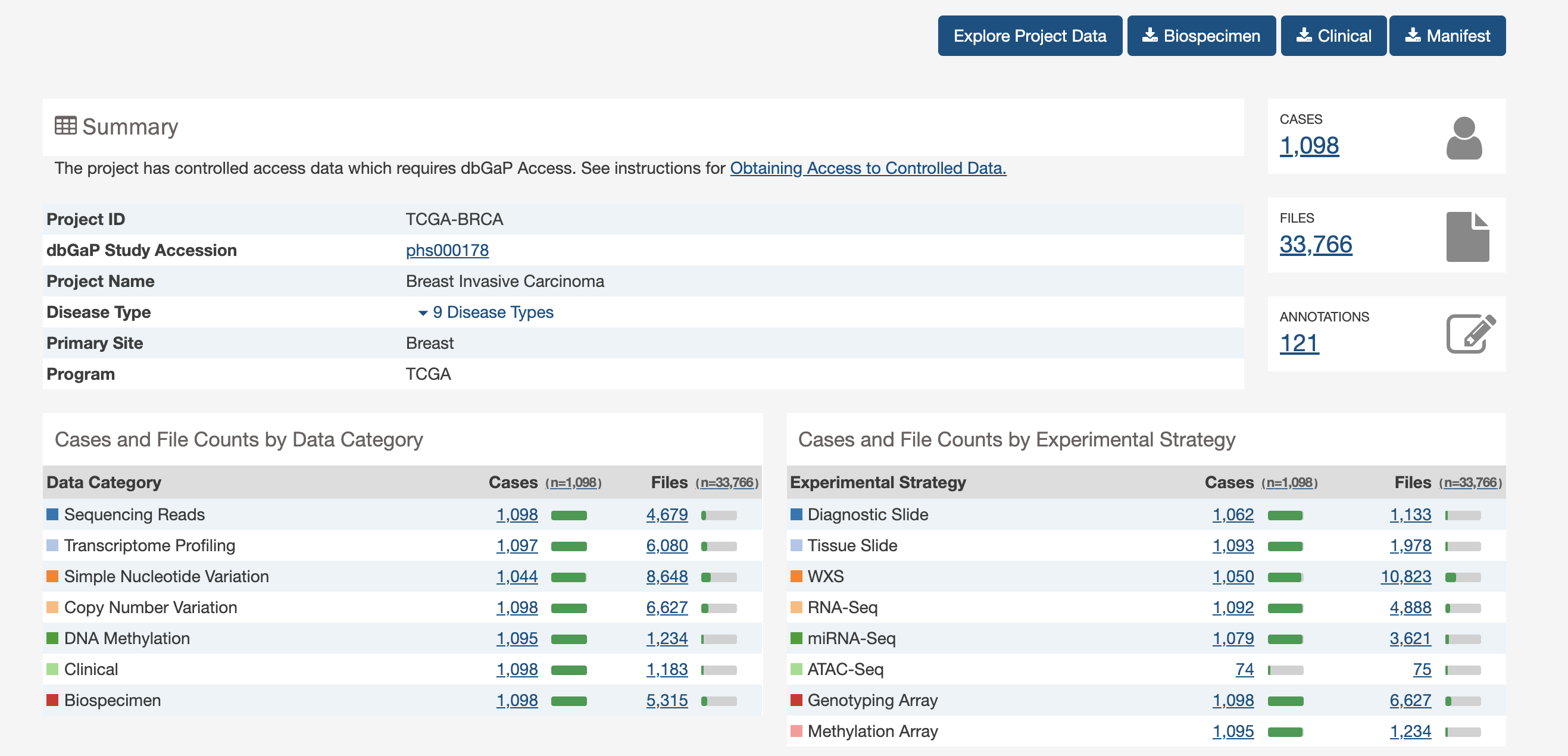
A lot of data of different types. Just transcriptome and (some) clinico-pathological data for now.
But you can go back and get more anytime you would like from the GDC
Scatterplot
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2))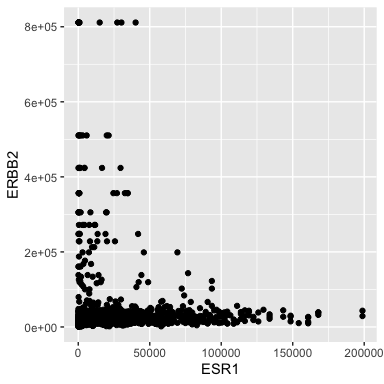
- ERBB2 is the official gene name for HER2.
- The \({\tt ggplot()}\) function is where it all begins. Here we specify the tibble that stores the data we are going to use.
- We add layers to the plot using the + operator. A \({\tt geom}\) species the type of geometric object. - Here we specify points for a scatterplot.
Scatterplot
Ok, I don’t like the black and the points are too big.
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2), color = "blue", size = 0.1)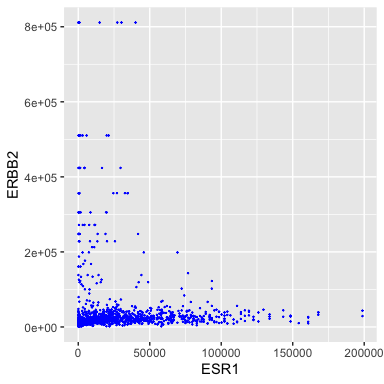
Aesthetic mappings
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2, color = tumor), size = 0.1)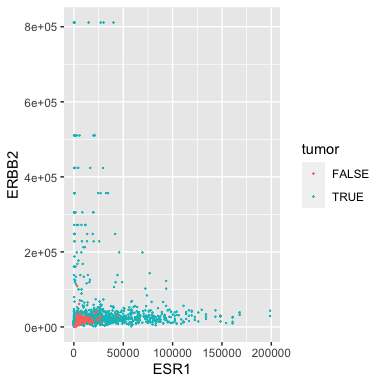
Some of our samples are tumors and some are matched normal. Perhaps not surprisingly, the normals have low expression of both oncogenes.
Note that the aesthetic (\({\tt aes}\)) contains a third argument \({\tt color}\) that uses the \({\tt tumor}\) attribute/column. Careful, note that the color is inside the \({\tt aes}\)!
Aesthetic mappings: Race
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2,
color = race), size = 1)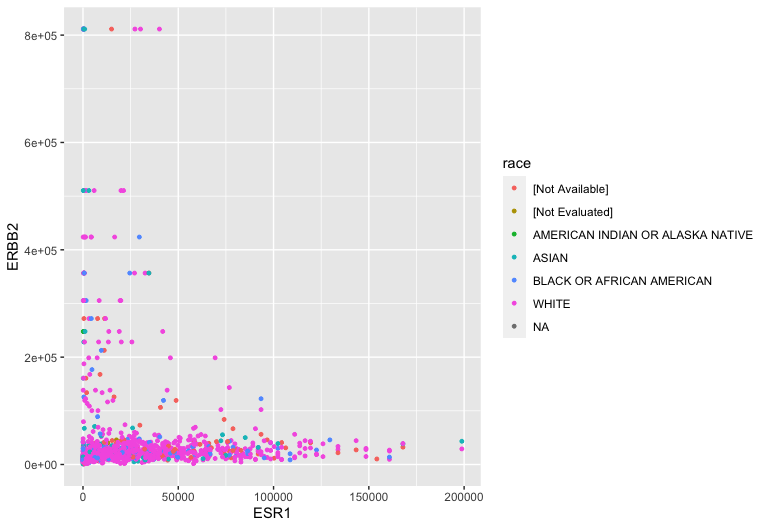
Aesthetic mappings: TNM staging
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2,
shape = tumor, color = ajcc_pathologic_tumor_stage), size = 1)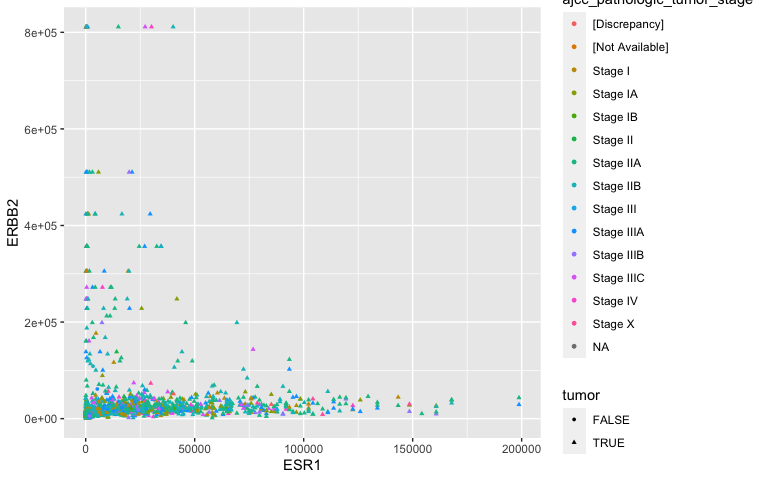
- A bit noisey
Facets: TNM staging revisited
- Facets partition the data (ESR1 vs HER2 expression) according to a third attribute (tumor stage). Notice the tilde (\(\sim\)). This species a formula (more about this later).
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2, color = tumor), size = 1) +
facet_wrap( ~ ajcc_pathologic_tumor_stage, nrow = 4)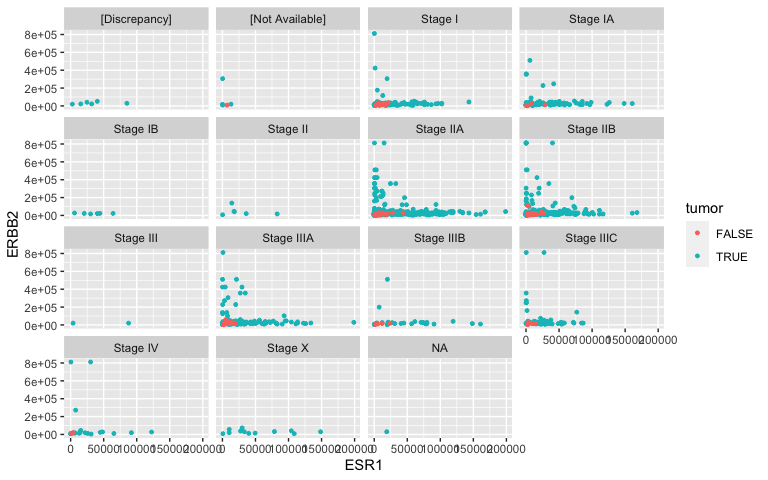
Facets: Histological Type
- I’m not too convinced in a relationship between ER, HER2 and TNM staging. What about histological type?
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ESR1, y = ERBB2, color = tumor), size = 1) +
facet_wrap( ~ histological_type, nrow = 4)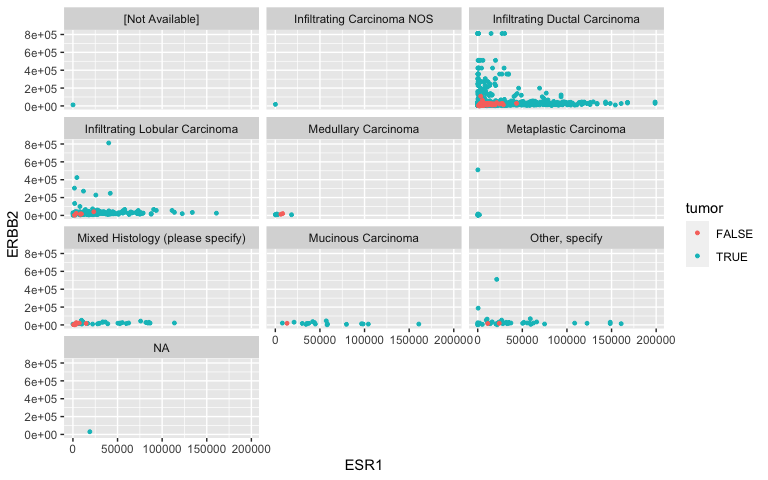
Geometric objects
- GRB7 and ERBB2 (aka HER2) show correlation in their expression. This makes sense because high expression of HER2 in BC is very often due to amplification of the chromosomal region that contains HER2. In some patients, this genomic locus is amplified (duplicated) 30-50x. GRB7 lies very close to HER2 in this so-called amplicon.
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ERBB2, y = GRB7, color = tumor), size = 1) 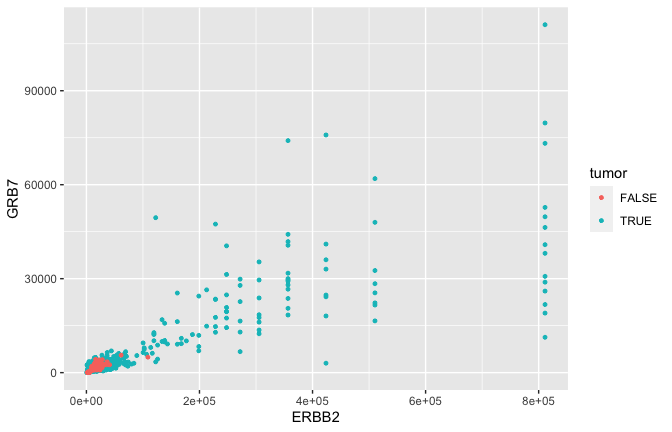
Smoothing
- Often we would just like to capture the essence of the relationship. Here for example that could be represented by a curve and a confidence interval \({\tt geom\_smooth}\) rather than the actual points \({\tt geom\_point}\).
ggplot(data = small_brca) +
geom_smooth(mapping = aes(x = ERBB2, y = GRB7, color = tumor), size = 1)
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'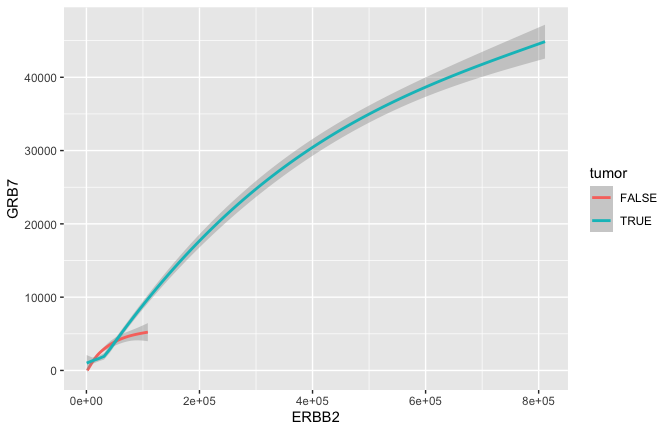
Smoothing
ggplot(data = small_brca) +
geom_smooth(mapping = aes(x = ERBB2, y = GRB7, linetype = tumor), size = 1)
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'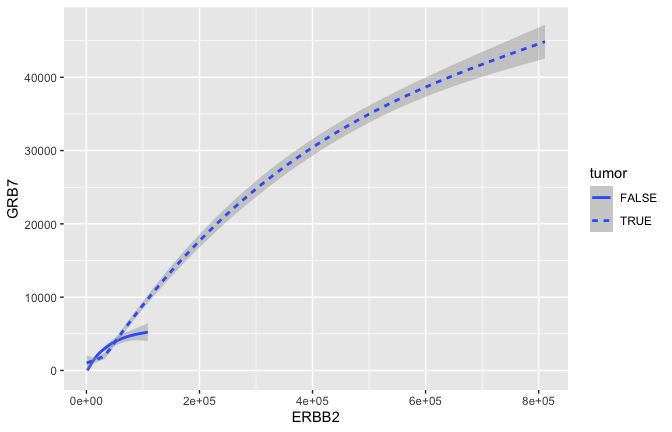
Smoothing
ggplot(data = small_brca) +
geom_point(mapping = aes(x = ERBB2, y = GRB7, color = tumor), size = 1) +
geom_smooth(mapping = aes(x = ERBB2, y = GRB7, linetype = tumor), size = 1)
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'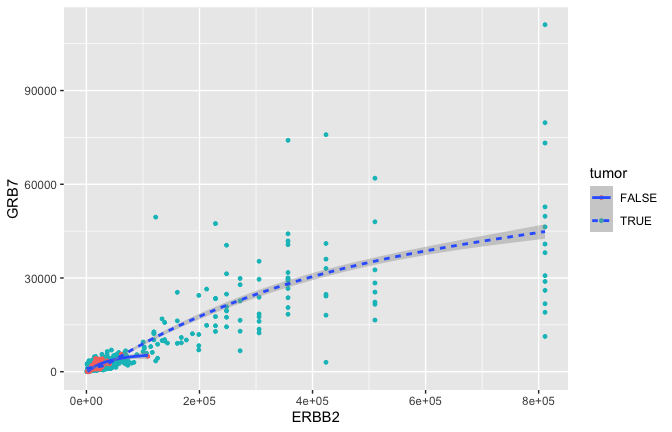
Statistical transformations
- Lymph node status has long been used by clinicians to measure how far a tumor has progressed. They count the number of positive lymph nodes and pay particular attention to the so-called sentinal lymph node (the one closest to the tumor).
ggplot(data = small_brca) +
geom_bar(mapping = aes(x=lymph_nodes_examined_count))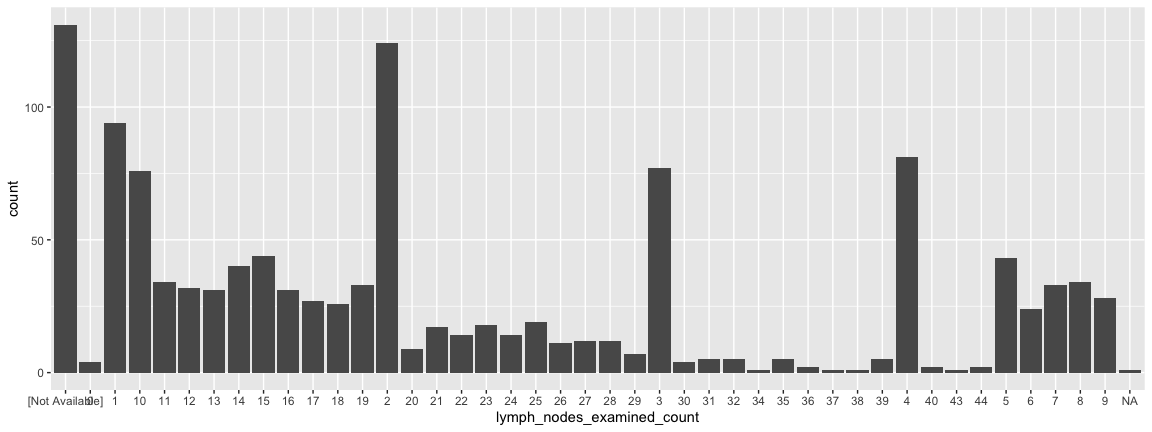
- It is possible to reorder the x-axis but not for today….
Statistical transformations are beautiful
ggplot(data = small_brca) +
geom_bar(mapping = aes(x=lymph_nodes_examined_count, fill = ajcc_pathologic_tumor_stage))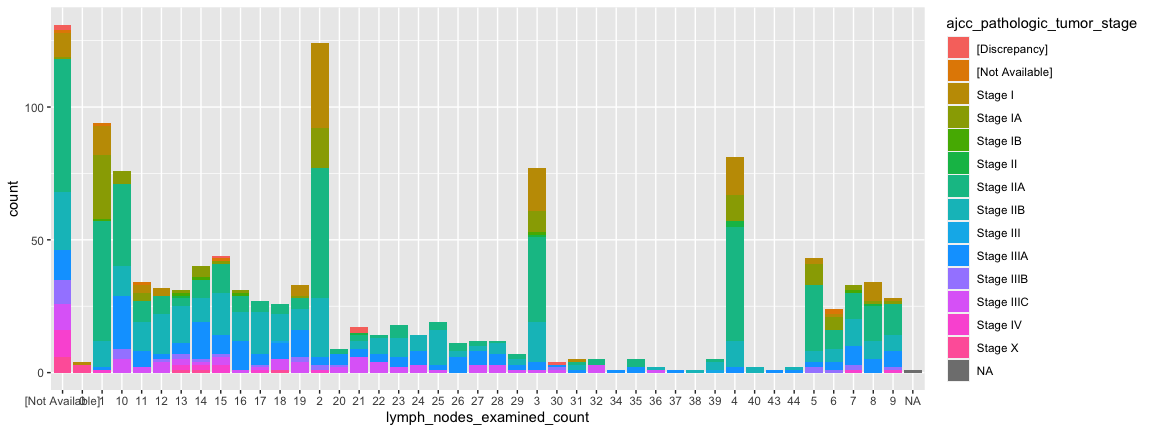
- Notice how low stages “disappear” in patients with many lymph nodes.
BIOCHEM xxxx
© M Hallett, 2022 Western University