Discovering subtypes in breast cancer: unsupervised analysis
M Hallett
21/07/2020
Global Thermonuclear War
(In RStudio, you can simply click Session/Interrupt R.)

Ti-99/4a
Supervised learning example
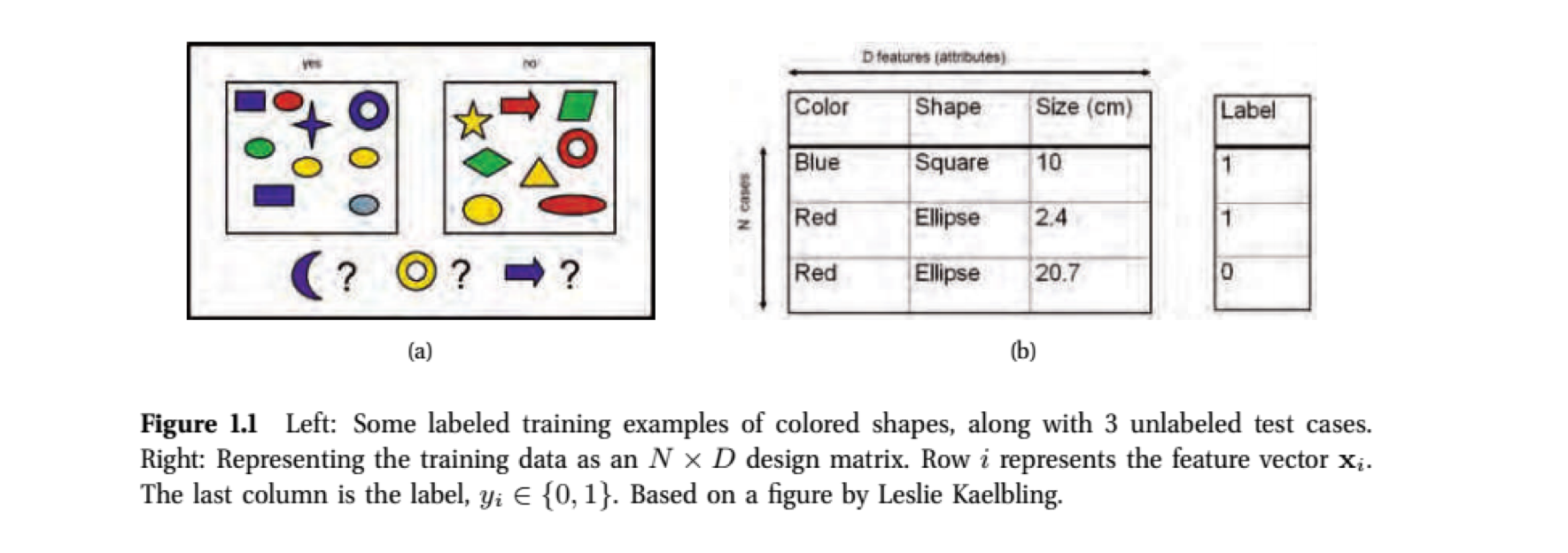
- The goal here is to generalize beyond the training set. That is, use the examples in the boxes of (a) and design matrix of (b) to form general rules that will allow us to classify the purple moon, yellow donut, and blue arrow.
Maximum a posterior probability (MAP)
- Recall the question from Michelle about a sort of likelihood/parsimony highbrid. MAP is a common approach; “best guess”:
- if \(Pr( y = {\tt good~outcome} | x, U) > Pr(y={\tt bad~outcome} | x, Y)\), choose good. Otherwise bad.
- Let’s revisit this puzzle with these concepts in mind.
Some real-world examples of supervised learning
- This data is available in R (\({\tt iris}\) variable). From R. Fisher. The goal is to build a classifier for the three types of irises: setosa, virginica, versicolor.

Real-world examples of supervised learning
- The features x are sepal length, sepal width, petal length, petal width (x[i, 1], x[i,2], x[i,3], x[i,4] four attributes). D is the data in the \({\tt iris}\) tibble in R. N, the number of examples in the learning set, is 150.
More examples


Regression
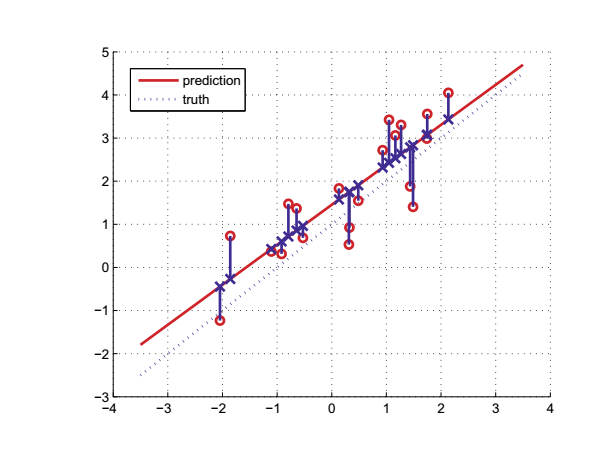
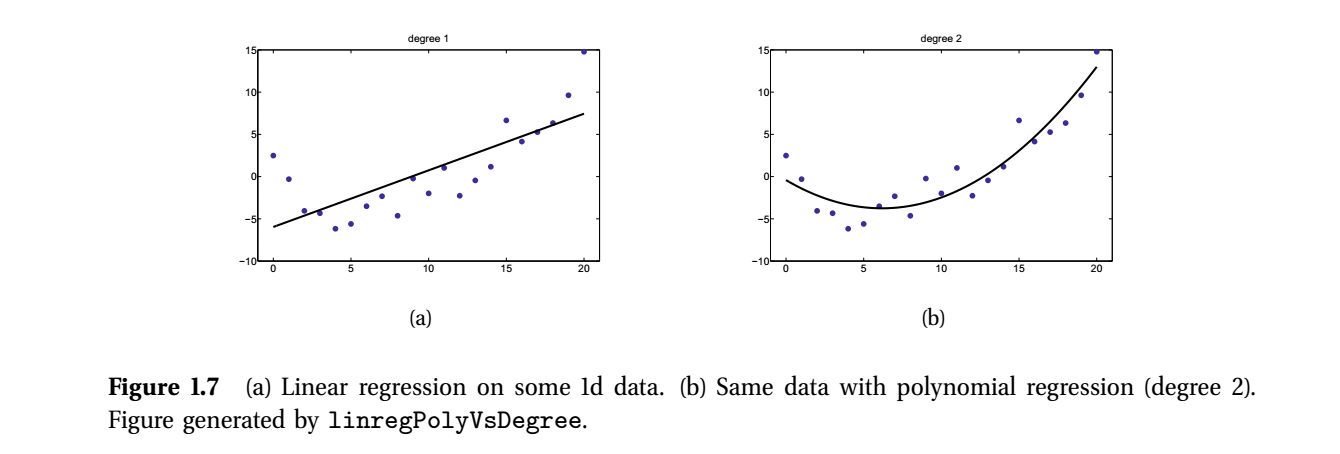
- Recall: Variable \(y\) (eg gender) is called the response variable. When \(y\) takes real values (eg age, time, temperature), we call this problem a regression.
BIOL 480
© M Hallett, 2020 Western University